Recent Thinking with Video approaches use Video Generation Models (VGMs) for visual reasoning by producing temporally coherent Chain-of-Frames as reasoning artifacts.
Even strong VGMs, however, exhibit two recurring failure modes on goal-directed tasks: long-horizon drift when a single prompt specifies a multi-step task, and mid-clip simulation errors that propagate through subsequent frames.
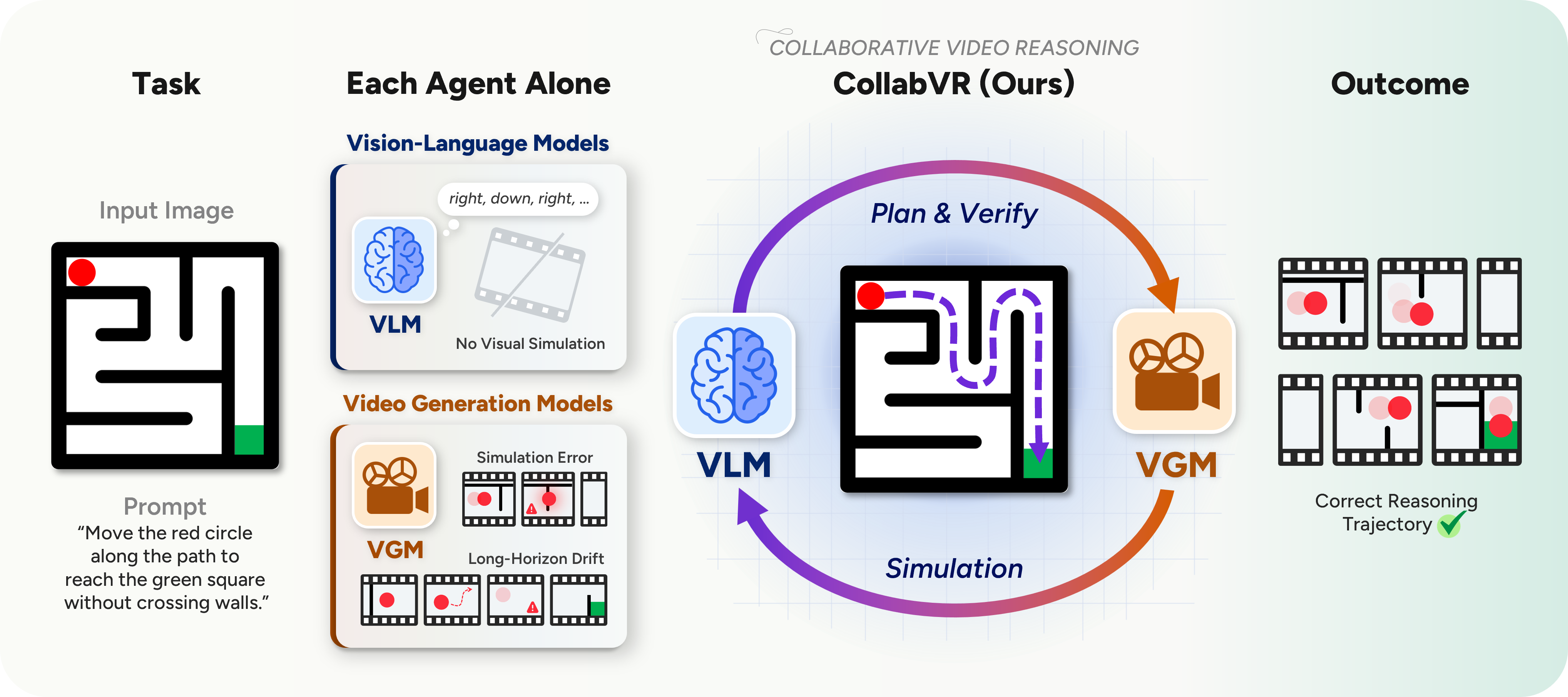
Both stem from the absence of explicit reasoning built upon the VGM's short-horizon visual prior, a role naturally filled by Vision-Language Models (VLMs), but where to place the VLM is non-trivial: upfront plans commit before any frame is generated and post-hoc critiques over whole videos intervene too late.
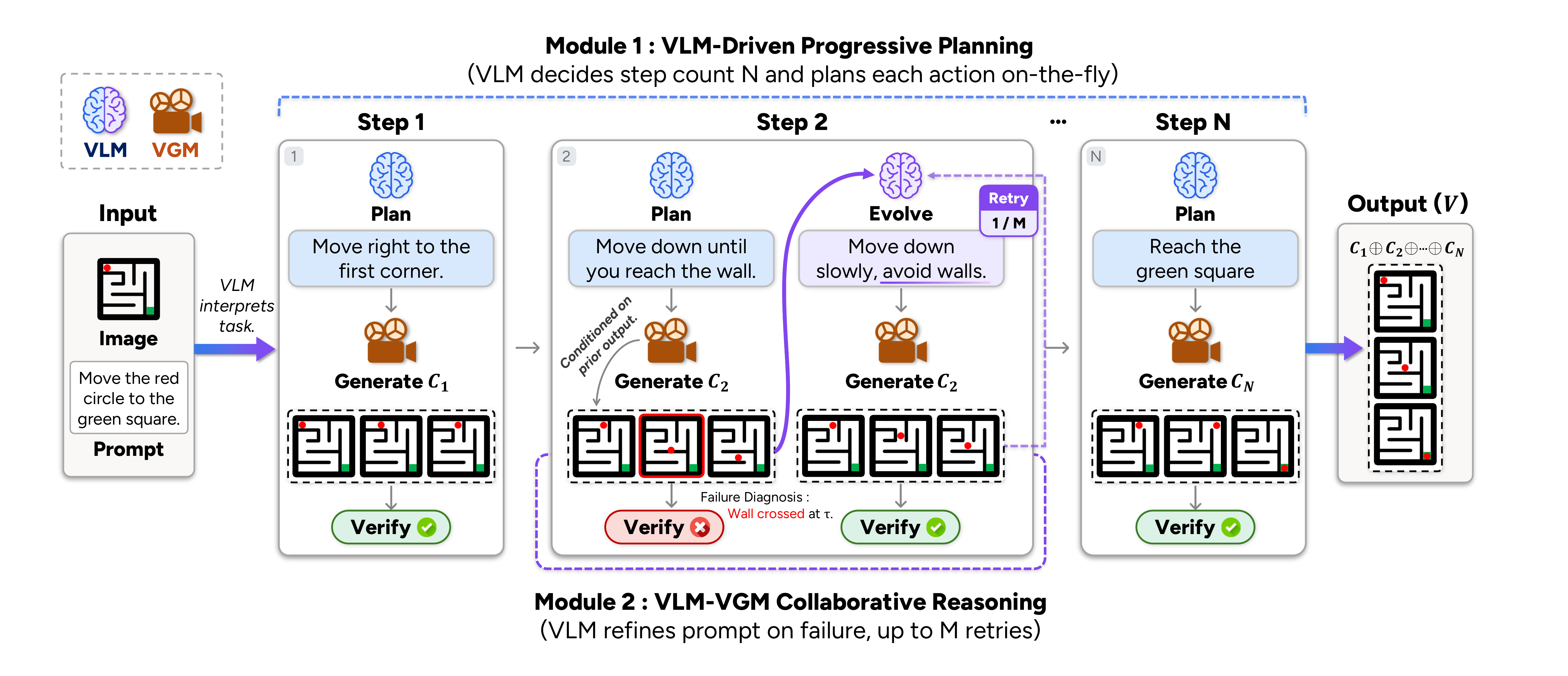
We propose CollabVR, a closed-loop framework that couples the VLM with the VGM at step-level granularity: the VLM plans the immediate next action, inspects the clip the VGM generates, and routes test-time compute across qualitatively distinct recovery strategies (re-generation, action splitting) matched to the diagnosed failure.
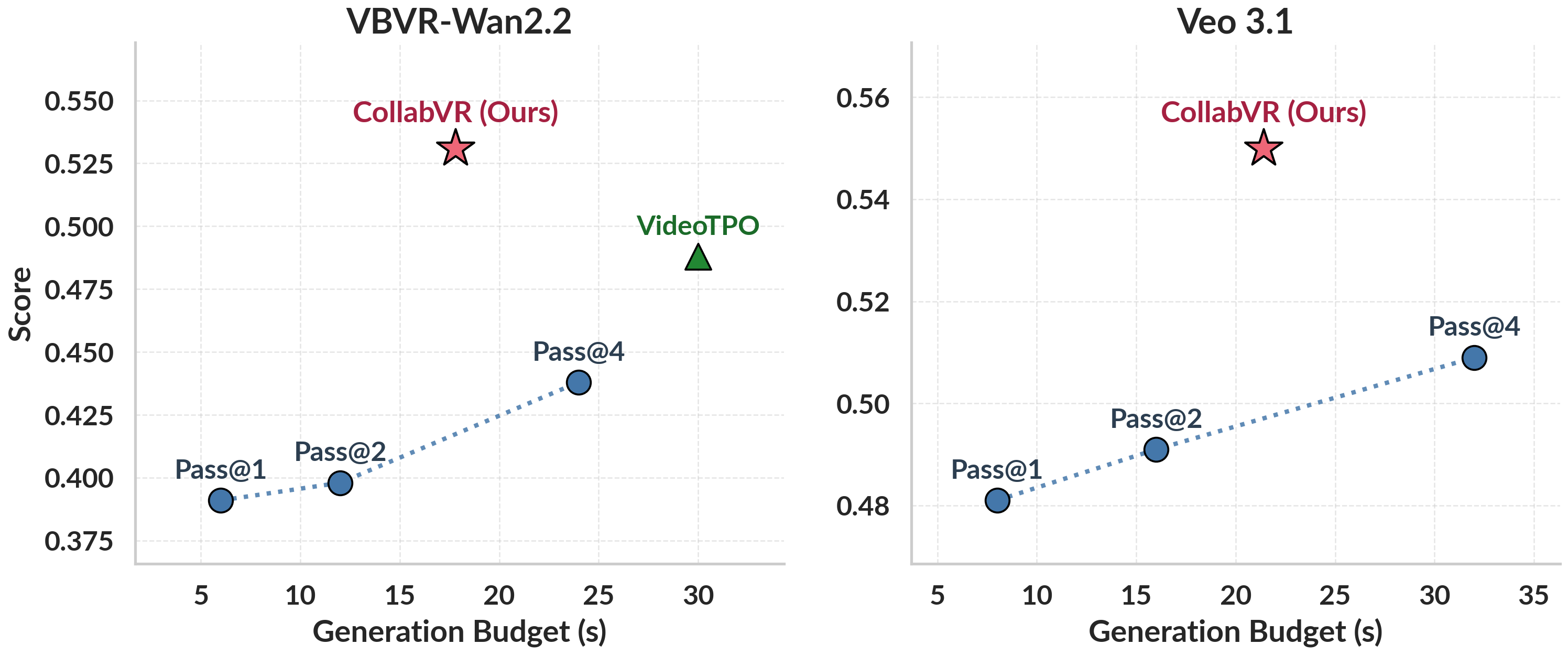
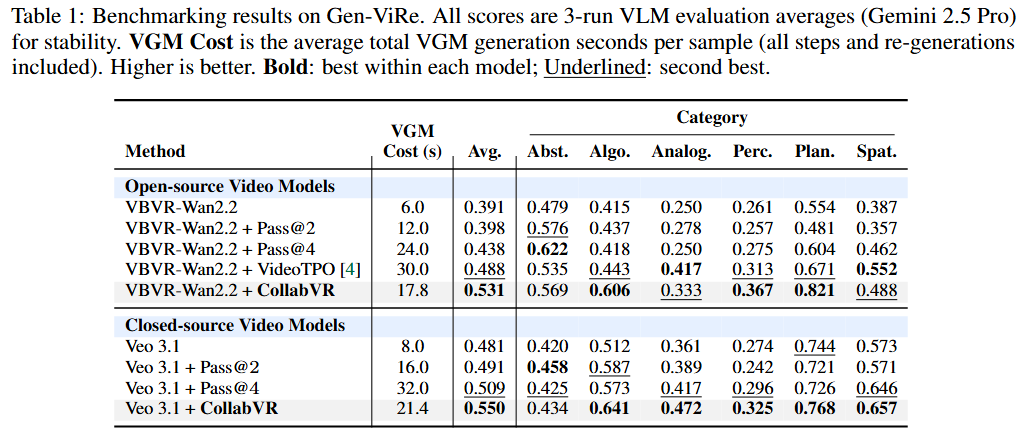
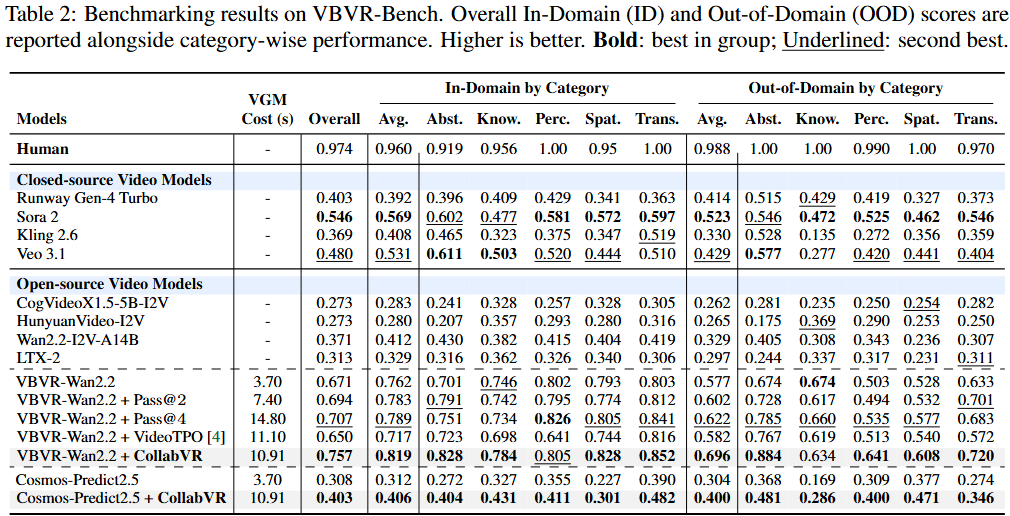
On Gen-ViRe and VBVR-Bench, CollabVR consistently improves both open-source and closed-source VGMs over single-inference, Pass@k, and prior video test-time scaling baselines at matched compute, with the largest gains on the hardest tasks.
It also yields further improvements on top of a reasoning-fine-tuned VGM, indicating that step-level VLM supervision is orthogonal to and stackable with reasoning-oriented fine-tuning.